Коли я кажу засновникам, що тепер вони можуть зібрати робочий бізнес-додаток за вечір, у відповідь часто чую тиху паніку. Не тому, що це складно — навпаки, стало надто легко. Паніка в іншому: «А я ж тепер сам відповідаю за дані. І за безпеку. І я в цьому не інженер».
Я будую продукти з AI сам — у Dronehub, в Oswin AI, у власних навчальних продуктах. Dronehub — це deep-tech, де до даних ставляться серйозно, без права на «та якось воно буде». І саме тому я хочу написати цей текст спокійно, без залякування. Безпека даних в AI-додатку — це не магія для обраних. Це набір дорослих звичок, які може засвоїти не-інженер. Не всі одразу, але по черзі — цілком.
Давайте розберемо їх по порядку. Не як юридичний трактат, а як те, на що я сам дивлюся, коли вирішую, що цьому додатку можна довірити.
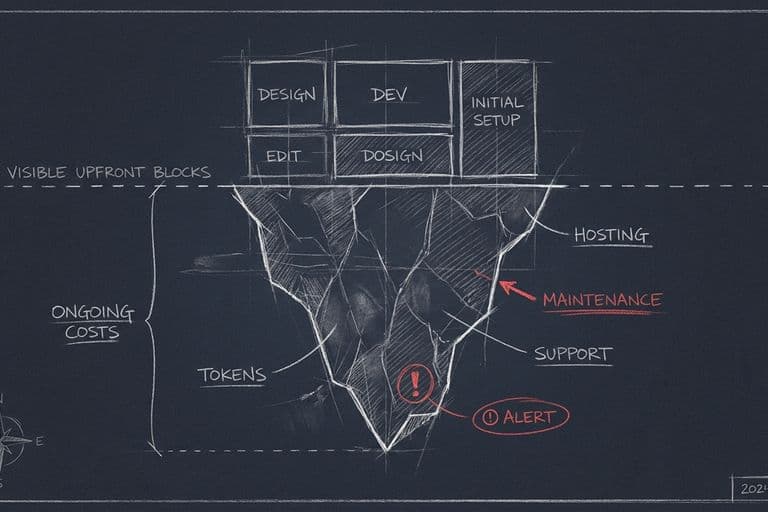
Перша звичка: давати моделі лише потрібний мінімум
Найголовніше рішення ви приймаєте ще до будь-якого коду — коли вирішуєте, які дані взагалі потраплять до моделі.
У GDPR є принцип, який варто винести за межі юриспруденції й зробити інженерним правилом. Він називається мінімізацією даних: збирати й обробляти треба лише те, що адекватне, релевантне й обмежене тим, що справді потрібно для конкретної мети. Звучить як формальність, а насправді це найкращий захист, який існує. Дані, яких ви не зібрали й не надіслали, неможливо втратити.
Перенесіть це на свій AI-додаток. Моделі потрібно підсумувати скаргу клієнта? Дайте їй текст скарги — але не весь профіль клієнта з адресою, номером картки й історією покупок. Потрібно класифікувати запит? Дайте сам запит, а не базу даних навколо нього. Щоразу, коли ви збираєтесь щось надіслати моделі, поставте одне питання: чи потрібно це їй для цього конкретного завдання? Якщо ні — не надсилайте.
Окрема категорія — персональні дані. За GDPR це будь-яка інформація про ідентифіковану або потенційно ідентифіковану людину: ім'я, email, номер телефону, а часто й комбінація непрямих ознак, за якими людину можна впізнати. Такі дані варто або не давати моделі взагалі, або знеособлювати перед відправкою — замінювати ім'я на «Клієнт А», вирізати номери. Це не параноя. Це та сама мінімізація, просто щодо найчутливішого.
Я не юрист і не даю юридичних гарантій — конкретику щодо GDPR, медичних чи фінансових даних звіряйте зі своїм юристом. Але як принцип проєктування «давай мінімум» працює завжди, незалежно від юрисдикції.
Друга звичка: розрізняти «дані для навчання» і «дані в запиті»
Це місце, де плутається майже кожен не-інженер. І саме звідси росте найбільший страх: «Якщо я дам AI свої дані, він на них навчиться, і завтра мій конкурент витягне їх із моделі».
Розведемо два поняття, бо це різні всесвіти.
Дані для навчання — це те, на чому модель училася. Вони «зашиті» в неї назавжди й формують її знання про світ. Цей процес відбувається у провайдера, на величезних масивах, і до вашого додатка стосунку не має.
Дані в запиті (у промпті) — це те, що ви надсилаєте моделі прямо зараз, щоб вона виконала завдання. Модель їх читає, відповідає — і на цьому все. Вони не стають частиною моделі. Це як різниця між освітою лікаря і тим, що ви розповіли йому на прийомі: одне формує його назавжди, інше залишається у вашій картці.
Тепер ключове, з перевіреного. Дані, які ви надсилаєте через офіційний API бізнес-провайдерів — наприклад, OpenAI — за замовчуванням не використовуються для навчання моделей. Ваш запит не робить модель «розумнішою» й не спливе в чужій відповіді. Це окреме питання від тимчасового зберігання: за замовчуванням провайдер може тримати логи запитів до 30 днів для контролю зловживань, після чого видаляє — окрім випадків, коли довше зберігання вимагає закон. Для частини enterprise-ендпоінтів доступне навіть нульове зберігання.
Що з цього випливає на практиці. По-перше, страх «модель навчиться на моїх даних» через бізнес-API здебільшого безпідставний — але перевіряйте умови саме того провайдера й саме того тарифу, яким користуєтесь, бо політики відрізняються. По-друге, безплатні споживчі чат-боти й API — це різні режими; не плутайте те, що написано для одного, з тим, що діє для іншого. По-третє, навіть якщо на навчання дані не йдуть, вони все одно кудись надсилаються й десь тимчасово лежать — тому звичка номер один (давати мінімум) нікуди не зникає.
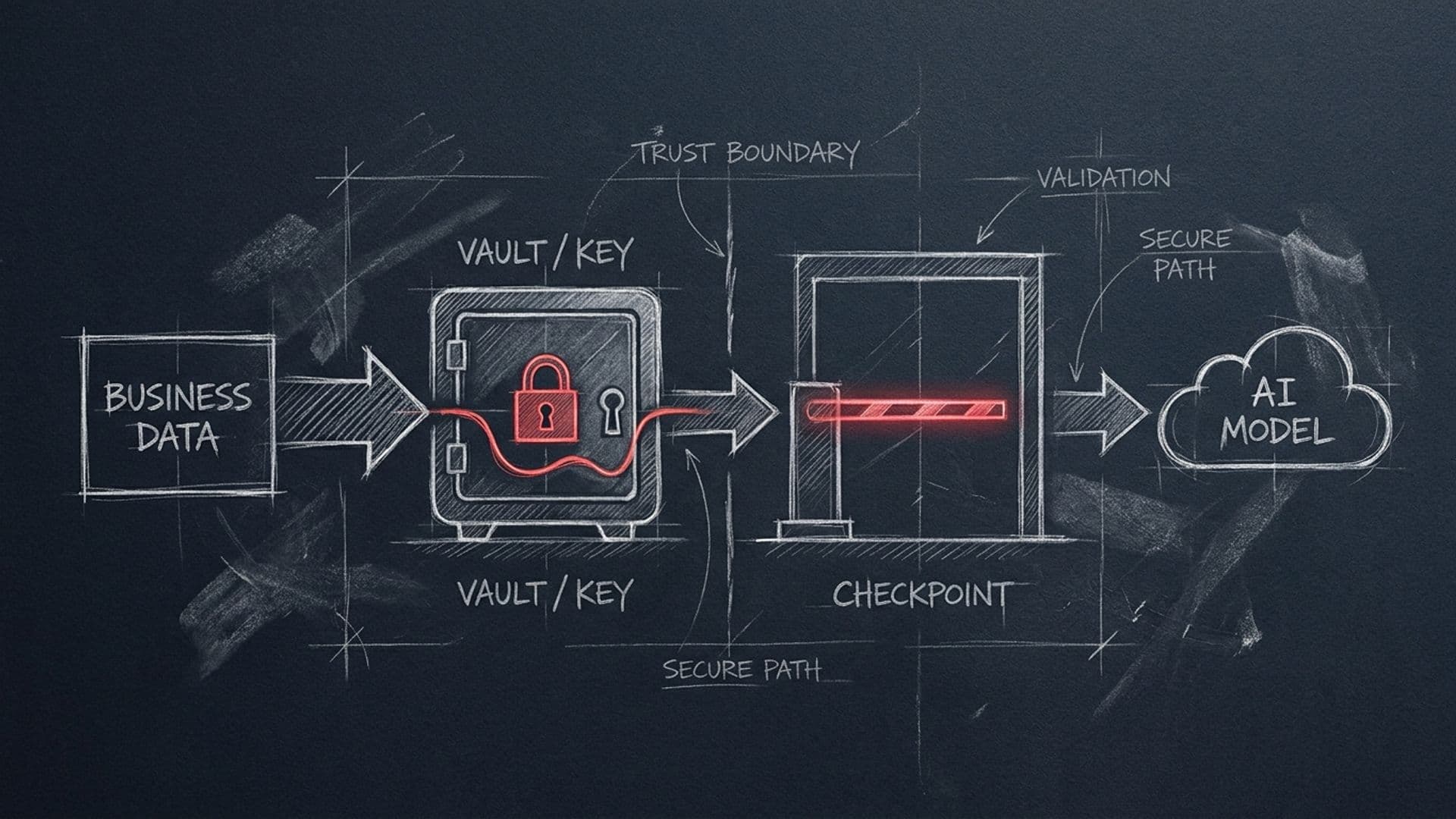
Третя звичка: тримати секрети окремо від коду й промптів
Це найчастіша й найдурніша діра, на яку я натикаюся в додатках, зібраних не-інженерами. І найлегша для виправлення.
Секрет — це ключ API, пароль до бази, токен доступу. Будь-що, що відмикає двері. І є просте правило: секрети не належать у код і не належать у промпти.
Чому це важливо. Коли ви вписуєте ключ прямо в код, він потрапляє не лише в сам файл. Він іде в історію git — і лишається там, навіть якщо ви потім його «видалите». Він спливає в логах, у скриншотах, у повідомленнях про помилки. Один скопійований у чат фрагмент коду з ключем усередині — і ключ уже не ваш. А ключ до платіжки чи до бази даних — це гроші й дані напряму.
Стандартна практика, яку варто засвоїти раз і назавжди: секрети зберігаються окремо від коду — у змінних оточення (звичайно це файл .env, який ніколи не потрапляє в git) або у спеціальному менеджері секретів. У самому коді ви звертаєтесь до секрету за іменем, а не за значенням. Код бачить «дай мені ключ під назвою OPENAI_KEY», а саме значення лежить у захищеному місці.
І ще одне, що багато хто пропускає: якщо секрет колись уже потрапив у репозиторій або кудись витік — його недостатньо видалити. Його треба відкликати й перевипустити. Видалений рядок усе ще живе в історії; єдиний надійний хід — зробити старий ключ недійсним і згенерувати новий.
Четверта звичка: доступи й ролі за принципом мінімуму
Той самий принцип «лише потрібний мінімум» працює не тільки для даних, а й для доступів.
Коли ваш AI-додаток підключається до бази, до пошти, до CRM — питання не «чи має він доступ», а «наскільки широкий цей доступ». Якщо завдання — читати замовлення, дайте йому право читати, а не право видаляти базу. Якщо інтеграція має надсилати листи, не давайте їй заразом ключі від адміністрування акаунту.
Це називається принципом найменших привілеїв, і логіка проста: коли (не «якщо») щось піде не так — помилка в коді, скомпрометований ключ, неправильний промпт — масштаб шкоди обмежений тим доступом, який ви видали. Вузький доступ перетворює катастрофу на прикрість.
Для не-інженера це звучить абстрактно, тож ось приземлено: створюйте окремі ключі й окремі ролі під кожну задачу, з мінімальними правами. Не використовуйте один всемогутній адмін-ключ скрізь. Так, це трохи більше налаштувань на старті. Але це різниця між «зламали одну функцію» і «зламали все».
П'ята звичка: перевіряти згенерований код, а не довіряти йому наосліп
Вайбкодинг — коли ви описуєте, що треба, а AI пише код — це чудо для швидкості. Я сам так збираю прототипи. Але тут є чесна засторога, яку я завжди проговорюю.
Модель пише код, який виконує завдання. Вона не пише код, який витримує атаку. Це різні цілі, і за замовчуванням оптимізується перша. Тому згенерований код регулярно приходить із типовими дірками: захардкоджені секрети, відсутня перевірка того, що ввів користувач, надмірні дозволи, застарілі чи вразливі залежності, недбала робота з базою, куди можна підсунути шкідливий запит.
Це не означає «не користуйтеся вайбкодингом». Це означає: між «воно працює» і «воно йде до реальних даних і платежів» має стояти перевірка. Для прототипу, який крутиться локально на вигаданих даних, можна не паритися. Але щойно додаток торкається справжніх клієнтів, грошей чи персональних даних — код має переглянути людина, яка розуміє безпеку. Якщо такої людини у вас немає, це окрема стаття витрат, яку треба закласти, а не вдавати, що її нема.
Корисний хід для не-інженера: попросіть саму модель переглянути власний код на вразливості, окремим запитом — «знайди проблеми безпеки в цьому коді». Це не замінює людину, але ловить найгрубіше. І звіряйтеся з відкритими переліками типових ризиків — спільнота OWASP веде такі списки і для звичайних застосунків, і окремо для додатків на основі мовних моделей.
Шоста звичка: людина в контурі на чутливих діях
Що автономніший ваш AI-додаток, то важливіше питання: де він зупиняється й питає дозволу?
Я ділю всі дії на дві купи. Перша — зворотні й дешеві: згенерувати чернетку, підсумувати текст, запропонувати варіант, розсортувати вхідні. Тут модель може діяти сама, бо ціна помилки — це «перепишемо». Друга купа — незворотні або дорогі: надіслати гроші, видалити дані, опублікувати щось від імені компанії, відповісти клієнту в делікатній ситуації, підписати документ. Тут між наміром моделі й виконанням має стояти людина, яка натисне «так».
Це і є «людина в контурі». Принцип, який я тримаю в голові: що дорожча або незворотніша дія, то ближче має бути людина. Не треба ставити підтвердження на кожен крок — це вб'є всю користь від автоматизації. Треба ставити його там, де помилку не відкотиш.
Для бізнесу це ще й питання довіри й відповідальності. Коли під делікатним рішенням стоїть людина, у вас є хто відповідає і хто може вчасно зупинити. Повністю автономна система, яка сама розсилає гроші чи спілкується з клієнтами без нагляду — це не сміливість, це необачність.
Сьома звичка: бекапи й вихід від вендора закладаються на старті
І останнє, найнудніше — а тому найчастіше пропущене.
Бекапи. Якщо ваш AI-додаток щось створює чи зберігає — дані клієнтів, згенерований контент, налаштування — у вас має бути копія, окрема від основної системи. Не тому, що зламають хакери, а тому, що зітреться випадково, помилиться скрипт, упаде провайдер. Бекап, який лежить там само, де оригінал — це не бекап. Перевіряйте, що з копії реально можна відновитися; неперевірений бекап — це обіцянка, а не страховка.
Вендор-лок. Коли ви будуєте на чужій платформі — на конкретній моделі, конкретному сервісі — ви добровільно прив'язуєтесь. На старті це непомітно й зручно. Боляче стає, коли ціна виросла, умови змінилися чи провайдер закрив потрібну функцію, а ви вже не можете легко піти. Захист закладається наперед: тримайте свої дані у себе й перевіряйте, що можете їх вивантажити; надавайте перевагу стандартним форматам і відкритим API, які підтримує не один постачальник; не вшивайте логіку так, щоб вона працювала лише в одному місці. Свобода піти — це не зрада вендору, це здорова гігієна.
Зведена таблиця: ризик, приклад, що робити
Ось як я тримаю все це в одній картинці. Сім ризиків, по яких варто пройтися перед тим, як пускати AI-додаток до справжніх даних.
Що з усім цим робити, якщо ви не інженер
Не намагайтеся закрити все одразу — так найпростіше здатися. Я б ішов по черзі.
Спершу — два рішення, що нічого не коштують, окрім уважності: давайте моделі мінімум даних і знеособлюйте персональні. Потім — секрети геть із коду, бо це найчастіша й найдешевша для виправлення діра. Далі — звузьте доступи. І лише коли додаток виходить за межі прототипу й торкається реальних клієнтів, грошей чи персональних даних — підключайте перевірку коду, людину в контурі на чутливих діях і нормальні бекапи.
Жоден із цих кроків не вимагає інженерного диплома. Вони вимагають дорослого ставлення до того, що вам довірили — а саме його, а не складність, я й вважаю справжньою безпекою. І ще раз, чесно: я ділюся принципами, а не юридичними гарантіями. Там, де йдеться про персональні дані, GDPR і галузеві вимоги, остаточне слово — за вашим юристом. Моя справа — щоб ви прийшли до того юриста, уже зробивши очевидне правильно.
Key facts
Дані, які ви надсилаєте через API провайдерів на кшталт OpenAI, за замовчуванням не використовуються для навчання моделей — модель «не запам'ятовує» ваш запит. Це окреме питання від того, чи провайдер тимчасово зберігає логи для контролю зловживань.
Source · OpenAI — How your data is used to improve model performance
За замовчуванням OpenAI зберігає вхідні й вихідні дані API до 30 днів для моніторингу зловживань, після чого видаляє — окрім випадків, коли довше зберігання вимагає закон. Для частини enterprise-ендпоінтів доступне нульове зберігання (zero data retention).
Source · OpenAI — Data controls in the OpenAI platform
За GDPR «персональні дані» — це будь-яка інформація, що стосується ідентифікованої або потенційно ідентифікованої фізичної особи: ім'я, номер, email, а часто й комбінація непрямих ознак, за якими людину можна впізнати.
Source · GDPR Article 4 — Definitions
Принцип мінімізації даних (стаття 5(1)(c) GDPR) вимагає збирати й обробляти лише ті персональні дані, які адекватні, релевантні й обмежені тим, що дійсно потрібно для конкретної мети.
Source · GDPR Article 5 — Principles relating to processing of personal data
Згенерований AI код регулярно містить вразливості — від захардкоджених секретів до SQL-ін'єкцій і небезпечної роботи з вводом користувача. Модель оптимізує «щоб працювало», а не «щоб було безпечно», тому перевірка людиною лишається обов'язковою.
Source · OWASP — Top 10 for LLM Applications
Секрети — ключі API, паролі, токени — не належать у код чи промпти. Стандартна практика: тримати їх у змінних оточення або в спеціальному менеджері секретів, окремо від коду й історії git.
Source · OWASP — Secrets Management Cheat Sheet
FAQ
- Чи можна давати AI-моделі конфіденційні дані компанії?
- Залежить від двох речей: що це за дані і через що ви їх надсилаєте. Через офіційний API бізнес-провайдерів ваші запити за замовчуванням не йдуть на навчання моделі. Але це не означає «можна все»: персональні дані клієнтів, медичні чи фінансові записи, комерційні таємниці варто або не надсилати взагалі, або знеособлювати перед відправкою. Правило просте: давайте моделі лише той мінімум, який потрібен їй для конкретного завдання.
- Яка різниця між «дані для навчання» і «дані в запиті»?
- Дані для навчання — це те, на чому модель училася й що вона «пам'ятає» назавжди. Дані в запиті (промпті) — це те, що ви надсилаєте моделі прямо зараз, щоб вона відповіла; після обробки запиту вони не стають частиною моделі. Через бізнес-API ваші запити за замовчуванням не використовуються для навчання. Плутанина між цими двома речами — джерело більшості страхів «AI вкраде мої дані».
- Де зберігати ключі API та паролі в AI-додатку?
- Не в коді й не в промптах. Захардкоджений ключ потрапляє в git-історію, в логи, в скриншоти — і звідти витікає. Стандарт: зберігати секрети у змінних оточення (.env-файл поза git) або в менеджері секретів, а в коді звертатися до них за іменем. Якщо секрет колись потрапив у репозиторій — його треба відкликати й перевипустити, а не просто видалити.
- Чи безпечний код, згенерований AI (вайбкодинг)?
- Він робочий, але не автоматично безпечний. Модель пише код, який виконує завдання, а не код, який витримує атаку. Типові дірки — захардкоджені секрети, відсутня перевірка вводу, надмірні дозволи, застарілі залежності. Вайбкодинг чудовий для швидкого прототипу, але перш ніж пустити такий код до реальних даних і платежів, його має переглянути людина, яка розуміє безпеку.
- Що таке «людина в контурі» і коли вона потрібна?
- Це коли перед чутливою дією AI зупиняється й чекає підтвердження людини. Згенерувати чернетку листа модель може сама. А ось надіслати гроші, видалити дані, опублікувати щось від імені компанії чи відповісти клієнту в делікатній ситуації — тут потрібна людина, яка натисне «так». Принцип простий: що дорожча або незворотніша дія, то ближче має бути людина.
- Як уникнути залежності від одного AI-вендора?
- Тримайте свої дані у себе, а не лише в системі постачальника, і регулярно перевіряйте, що можете їх вивантажити. Надавайте перевагу стандартним форматам і відкритим API, які підтримує не один провайдер. І робіть бекапи — окремі від основної системи. Лок-ін рідко відчувається на старті; він боляче проявляється, коли ви вже залежні, а умови змінюються.