Десь раз на тиждень до мене приходить засновник із приблизно однаковою фразою: «Вадиме, ми впровадили AI, але грошей це не принесло». І коли ми починаємо розбирати, що саме «впровадили», виявляється та сама картина, яку я бачу роками. Помилка майже ніколи не в технології. Вона в тому, як до технології підійшли.
Я навчаю підприємців AI й автоматизації у VADYM.AI та KIERUNEK.AI, паралельно сам впроваджую це все в Dronehub і в Oswin AI. Тобто я і той, хто наступає на граблі, і той, хто потім дивиться, як на ті самі граблі наступають інші. За цей час набрався доволі чіткий список повторюваних помилок. Він не унікальний для України — те саме показують і великі дослідження. За звітом MIT «The GenAI Divide» 2025 року, 95% корпоративних пілотів генеративного AI не дали жодного вимірюваного впливу на прибуток. Не тому, що моделі погані. Тому, що їх неправильно вбудовували.
Нижче — дев'ять помилок, які я бачу найчастіше. Для кожної я поясню, чому вона взагалі виникає, і як зробити правильно. У кінці буде таблиця, яку можна роздрукувати й повісити перед очима.
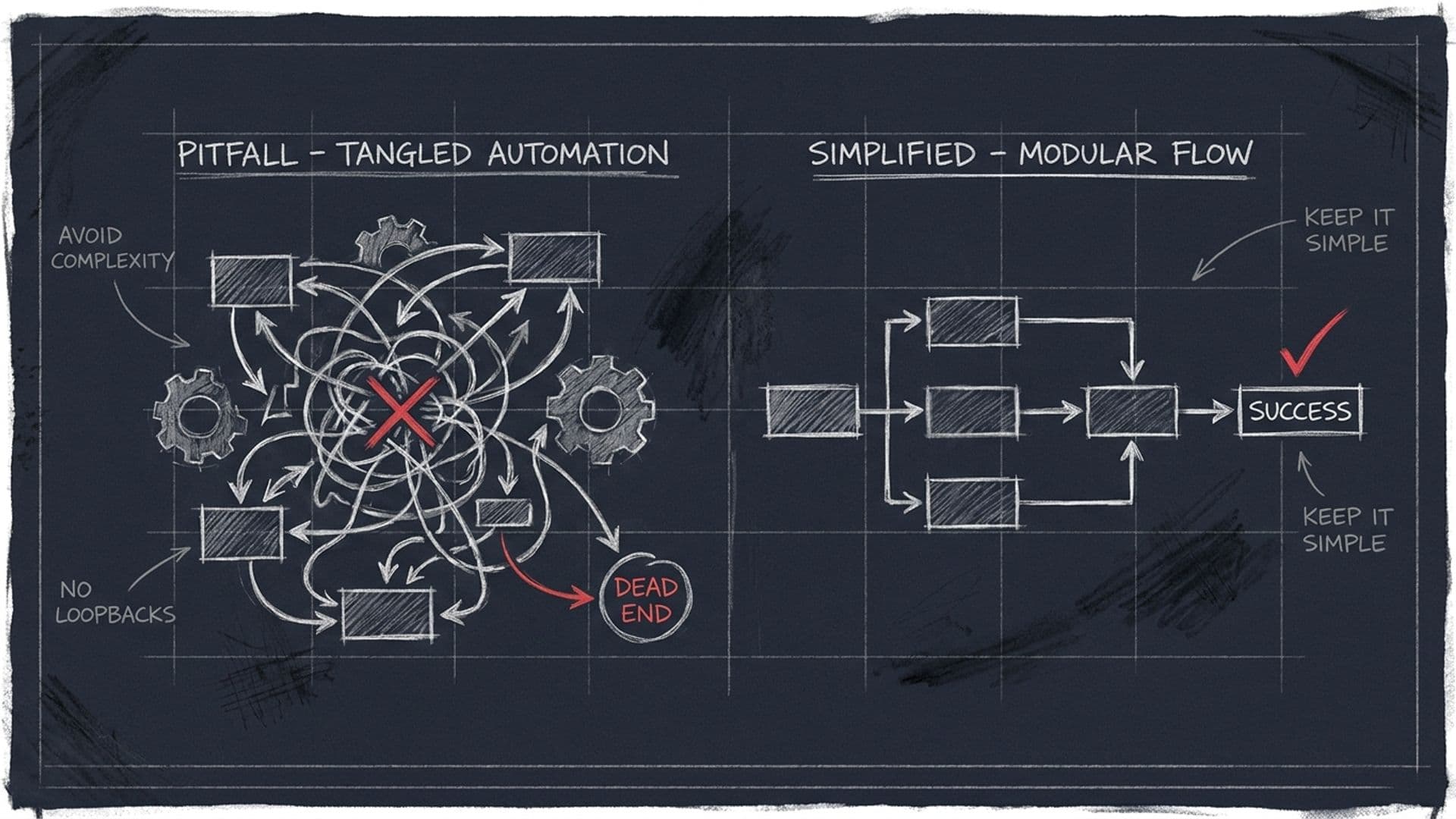
1. Автоматизувати хаос замість спершу спростити процес
Це помилка номер один, і вона найдорожча. Підприємець має заплутаний процес — десять різних чатів, ручні таблиці, домовленості «на словах», три винятки з кожного правила — і вирішує: «накину сюди AI, він наведе лад». Не наведе. AI не прибирає безлад, він його масштабує. Ви просто отримуєте той самий хаос, але швидший і дорожчий.
Чому так виходить? Бо автоматизація відчувається як прогрес, а спрощення відчувається як нудна робота. Сісти й переписати процес — це непомітна праця без вау-ефекту. Підключити AI — це ефектне демо, яке можна показати команді. Тому всі біжать одразу до другого кроку.
Правильно навпаки. Спершу візьміть процес і спростіть його руками, без жодної технології. Викиньте зайві кроки, приберіть винятки, які можна не робити, опишіть те, що залишилось, простими словами. Дуже часто на цьому етапі виявляється, що половину процесу взагалі не треба автоматизувати — її треба скасувати. І лише чистий, описаний процес має сенс віддавати машині. Правило просте: якщо ви не можете пояснити процес стажеру за п'ять хвилин, AI його теж не зрозуміє.
2. Купувати інструмент під хайп, а не під задачу
Виходить нова гучна модель чи сервіс — і починається. «Усі беруть, треба й нам». Купується підписка, виділяється бюджет, а через місяць інструмент стоїть мертвим, бо ніхто так і не сформулював, яку конкретну задачу він мав закрити.
Корінь тут — страх відстати. У 2025-му AI-новин стільки, що здається, ніби кожен тиждень виходить щось, без чого ви програєте. Це ілюзія. Інструмент без задачі — це не інвестиція, це витік грошей і уваги.
Правильний порядок зворотний: спершу задача, потім інструмент. Запишіть конкретно, що болить — «менеджери витрачають по дві години на день на однотипні відповіді клієнтам». Це задача. Під неї вже можна підбирати рішення й чесно міряти, чи стало краще. Хайп — поганий радник; нудна формула «болить отут, коштує стільки, економить стільки» — добрий. Я сам не раз купував гучне й потім тихо відписувався, бо так і не знайшов, куди це прикласти.
3. Чекати магії замість ітерацій
Дуже поширене очікування: підключив AI — і одразу маєш ідеальний результат. Перша ж відповідь виходить кривою, людина розчаровується й робить висновок «AI не працює». Насправді не працює підхід «запустив і пішов».
Звідки береться це очікування? З маркетингу й демо. У роликах усе виходить з першого разу, бо ролики й знімають доти, доки не вийде. У реальності AI — це не чарівна кнопка, а інструмент, який треба налаштовувати ітераціями: уточнити інструкцію, дати приклади, обмежити формат, перевірити на десяти реальних випадках, поправити.
Правильний режим — це цикл. Запустили на маленькій вибірці, подивилися, де помиляється, підкрутили, повторили. Перші версії завжди сирі — це нормально, а не привід кидати. Власне, MIT прямо вказує: виживають ті 5% проєктів, які не зупинилися на демо, а довели один вузький кейс до робочого стану через ітерації. Магії немає. Є дисципліна повторення.
4. Ігнорувати якість даних
AI годується вашими даними. Якщо дані брудні — дублі клієнтів, застарілі ціни, той самий контакт у трьох написаннях, таблиці, які ніхто не оновлював пів року, — то й відповіді будуть брудні. «Сміття на вході — сміття на виході» нікуди не поділося, AI лише зробив це швидшим.
Чому цю помилку так легко зробити? Бо дані — невидима частина. Гарний інтерфейс видно, а от той факт, що під ним лежить база з протиріччями, не видно, доки не почнуться дивні відповіді. Тому всі думають про модель і майже ніхто — про те, чим її годують.
А саме дані — найчастіша причина провалу. За оцінкою Gartner, близько 85% AI-проєктів падають саме через погану якість або брак релевантних даних. За опитуванням Informatica, лише 12% організацій мають дані достатньої якості для AI. Тобто це не рідкісна біда, це норма. Правильний крок — навести лад у даних до того, як підключати розумні інструменти. Один достовірний, прибраний джерело даних дасть кращий результат, ніж найдорожча модель поверх хаосу.
5. Без людини в контурі на ризикових діях
AI помиляється впевнено. У цьому головна підступність: він дає неправильну відповідь тим самим спокійним тоном, що й правильну. Тому віддавати йому повний контроль над ризиковими діями — надсиланням листів клієнтам, проведенням платежів, змінами в договорах, видаленням даних — це питання не «чи станеться помилка», а «коли і наскільки дорого».
Помилку роблять із бажання отримати максимум автоматизації якнайшвидше. «Хай уже все робить сам» звучить як мрія про ефективність. Але одна впевнена помилка в чутливій дії може коштувати дорожче, ніж уся економія за рік.
Правильно — лишати людину в контурі там, де ціна помилки висока. AI готує, людина підтверджує. Це не недовіра до технології, це нормальна інженерна обережність. Прибирати підтвердження можна лише там, де помилка дешева, а обсяг великий — і тільки після того, як ви побачили реальну статистику якості на сотнях випадків. Спершу заробіть довіру цифрами, потім знімайте запобіжник.
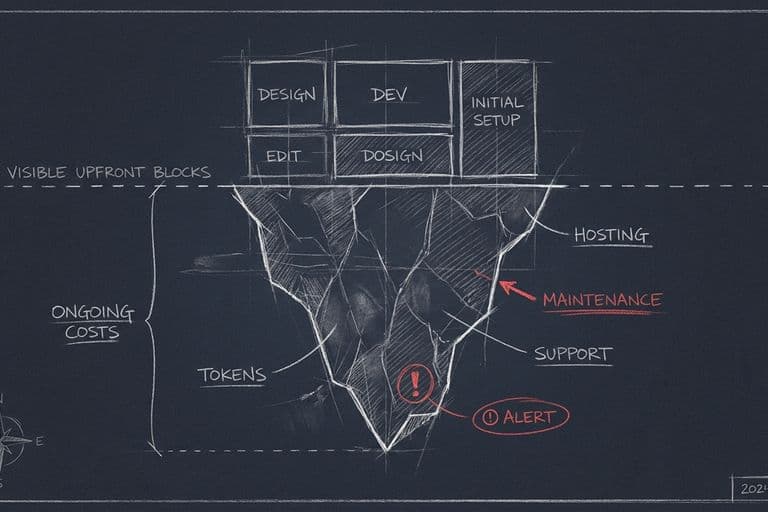
6. Не рахувати реальну вартість і окупність
Класична картина: AI «начебто допомагає», усім подобається, а коли питаєш «скільки він приніс або зекономив у грошах» — тиша. Проєкт живе на відчутті користі, а не на цифрі. І рано чи пізно його закривають, бо нічим виправдати.
Чому не рахують? Бо рахувати незручно. Видима вартість — це підписка, умовні двадцять доларів на місяць, і вона мала. А справжня вартість захована: токени й виклики API на обсязі, час людей на перевірку відповідей, моніторинг, оновлення під нові версії моделей, вартість самих помилок. Усе це не стоїть у прайсі, тому про нього забувають.
Правильно — рахувати не ціну запуску, а повну вартість володіння й чистий ефект. З одного боку всі реальні витрати, з іншого — конкретна зекономлена чи зароблена сума. Якщо різниця не очевидна, це не бізнес-проєкт, а хобі за гроші компанії. До речі, MIT показує, де віддача реальна найчастіше: не в ефектних фронтенд-демо, а в нудній автоматизації бек-офісу — там, де видно, скільки годин чи аутсорсу ви прибрали. Шукайте окупність там, де її легко порахувати.
7. «Один великий проєкт» замість малих перемог
Спокуса велика: «зробімо одразу велику AI-систему, яка перебудує весь відділ». Виділяється бюджет на пів року, збирається команда, малюються діаграми. А за пів року виявляється, що нічого не запустилося, гроші згоріли, а команда втратила віру, бо так і не побачила жодного результату.
Ця помилка — від амбіцій і від нерозуміння, що AI-впровадження непередбачуване. Великий проєкт виглядає солідно, його приємно презентувати інвесторам чи раді. Але він складає всі ризики в одну точку: якщо щось не злетіло, не злетіло все відразу.
Правильний шлях — нанизувати малі перемоги. Беріть одну вузьку задачу, яку можна довести до користі за два тижні. Запустили, показали цифру, отримали довіру команди — далі наступна. Кожен маленький результат фінансує й виправдовує наступний крок, а ви вчитеся на дешевих помилках, а не на одній дорогій. Велика трансформація — це не один стрибок, це двадцять маленьких кроків, кожен з яких уже окупився.
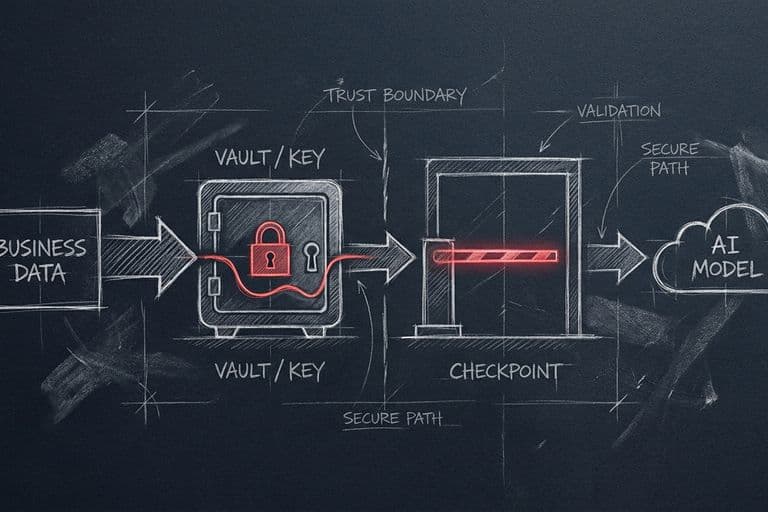
8. Недбалість із даними й приватністю
У запалі впровадження легко почати вставляти в перший-ліпший AI-сервіс усе підряд: бази клієнтів, договори під NDA, фінансову звітність, листування. Швидко, зручно — і одного дня дорого, коли виявляється, що чутливі дані пішли туди, куди не мали б, або що сервіс на них ще й навчався.
Помилка йде від азарту й від невидимості ризику. Поки нічого не сталося, приватність здається бюрократичною дрібницею, що сповільнює роботу. Аж до моменту, коли вона стає головною проблемою — зі штрафами за GDPR і втратою довіри клієнтів.
Правильно — від початку розділяти дані за чутливістю. Публічне й нечутливе можна сміливо віддавати будь-куди. А персональні дані клієнтів, комерційну таємницю й документи під угодами — лише в сервіси, де ви перевірили умови: чи навчаються вони на ваших даних, де ті зберігаються, чи це відповідає закону. Для чутливого існують окремі бізнес-тарифи з гарантіями, локальні моделі й знеособлення даних перед відправкою. Це не паранойя — це гігієна, яка коштує копійки наперед і шалені гроші постфактум.
9. Впроваджувати без власника й без навчання команди
Дев'ята помилка зшиває всі попередні. Інструмент купили, налаштували, показали команді на одній зустрічі — і пішли далі. За місяць ним ніхто не користується. Не тому, що він поганий, а тому, що в нього немає господаря і ніхто до пуття не навчився.
AI змінює не лише процеси, а й звички людей, а звички так просто не перемикаються. Якщо у впровадження немає конкретної людини, відповідальної за результат, і немає нормального навчання, інструмент тихо вмирає — навіть найкращий. Власне, MIT і називає головною причиною провалів не якість моделей, а «розрив у навчанні» інструментів і організацій: технологію впровадили, а людей і процеси під неї не підтягнули.
Правильно — у кожного AI-впровадження має бути власник, який відповідає за те, щоб ним користувалися й щоб він приносив результат. І має бути навчання — не одна презентація, а нормальне введення в роботу, з прикладами на реальних задачах команди. Технологія без людини, яка за неї відповідає, — це не актив, а майбутній технічний борг.
Таблиця: дев'ять помилок і що робити натомість
Що з усім цим робити
Якщо звести дев'ять помилок до одного речення, воно буде таким: AI не рятує від відсутності системи, він її лише підсвічує. Усі провальні впровадження, які я бачив, об'єднує одне — спроба перестрибнути нудну роботу. Не спростити процес, не прибрати дані, не порахувати гроші, не навчити людей, а одразу до ефектного результату.
Тому моя порада завжди однакова й трохи розчаровує тих, хто прийшов по магію. Почніть з малого. Візьміть одну болючу, вузьку задачу. Спростіть процес навколо неї руками. Приберіть дані, які до неї входять. Підберіть інструмент саме під неї, а не під заголовки. Запустіть із людиною в контурі. Порахуйте, скільки це зекономило. І лише коли побачите цифру — беріть наступну задачу.
Це не звучить як революція. Зате це працює — на відміну від тих 95% пілотів, які лишилися красивими демо. Революцію вам згодом нарахують ті двадцять маленьких кроків, кожен з яких уже окупився.
Key facts
За дослідженням MIT «The GenAI Divide: State of AI in Business 2025», 95% корпоративних пілотів генеративного AI не дали жодного вимірюваного впливу на прибуток. Значущу цінність створили лише близько 5% інтегрованих систем.
Source · MIT — The GenAI Divide: State of AI in Business 2025
Головна причина провалу, за MIT, — не якість моделей, а «розрив у навчанні» інструментів і організацій: невдала інтеграція в реальні процеси, а не слабкий AI.
Source · MIT — The GenAI Divide: State of AI in Business 2025
За оцінкою Gartner, близько 85% AI-проєктів зазнають невдачі через погану якість даних або брак релевантних даних.
Source · Gartner (за оглядом Fullview — AI Statistics 2025)
У 2025 році 42% компаній відмовилися від більшості своїх AI-ініціатив — різке зростання проти 17% у 2024-му.
Source · S&P Global Market Intelligence (за оглядом Fullview — AI Statistics 2025)
За опитуванням Informatica CDO Insights 2025, лише 12% організацій мають дані достатньої якості й доступності для AI; готовність даних назвали головною перешкодою 43% респондентів.
Source · Informatica — CDO Insights 2025
За даними MIT, найвищу віддачу дає автоматизація бек-офісу: спрощення процесів, скорочення аутсорсингу й зменшення витрат, а не ефектні фронтенд-демо.
Source · MIT — The GenAI Divide: State of AI in Business 2025
FAQ
- З якої помилки починається більшість провальних AI-впроваджень?
- З автоматизації хаосу. Підприємець бере заплутаний, недокументований процес і накидає згори AI, сподіваючись, що технологія наведе лад. Виходить навпаки: ви масштабуєте безлад і робите його ще швидшим. Спершу спростіть і опишіть процес руками — і лише потім автоматизуйте те, що залишилося.
- Чому 95% AI-пілотів не дають результату?
- За дослідженням MIT 2025 року, причина не в якості моделей, а в розриві між пілотом і реальним процесом. Компанії роблять ефектне демо, але не вбудовують AI у щоденну роботу, не міряють вплив на прибуток і не ітерують. Виживають ті 5%, що довели один вузький кейс до грошей, а потім розширили.
- Як правильно рахувати окупність AI-рішення?
- Рахуйте не вартість запуску, а вартість володіння й чистий ефект за рік. До цінника додайте токени й підписки на API, час людей на перевірку відповідей, моніторинг, оновлення під нові версії моделей і вартість помилок. Поряд поставте конкретну зекономлену чи зароблену суму. Якщо різниця не очевидна — це не проєкт, а хобі.
- Чи потрібна людина в контурі, якщо AI добре працює?
- На ризикових діях — обов'язково. AI помиляється впевнено, тому на всьому, що стосується грошей, договорів, листів клієнтам чи видалення даних, має бути крок підтвердження людиною. Прибирати людину з контуру можна лише там, де ціна помилки низька, а обсяг великий — і тільки після того, як ви побачили статистику якості.
- Один великий AI-проєкт чи багато малих?
- Багато малих. Великий проєкт «на пів року» згоряє бюджет і довіру команди ще до першого результату. Беріть одну вузьку задачу, яку можна довести до користі за два тижні, доведіть її, покажіть цифру — і лише тоді беріть наступну. Малі перемоги нанизуються; один великий провал зупиняє всю програму.
- Які дані можна віддавати в AI-сервіси?
- Не віддавайте персональні дані клієнтів, комерційну таємницю чи документи під NDA у сторонні сервіси без перевірки умов обробки. З'ясуйте, чи навчаються вони на ваших даних, де ті зберігаються і чи відповідає це GDPR. Для чутливого — окремі бізнес-тарифи з гарантіями, локальні моделі або знеособлення даних перед відправкою.